Introduction
This page seeks to answer the following question:
How does ProgSynth works at a high level?
Table of contents:
What do you give in?
ProgSynth only needs two things: a language to work on and a check function.
The provided language is called a domain specific language (DSL). The different kind of functions that can manipulate your data are provided and the framework will automatically generate the associated grammar. Specifyign a language with its types is quite fast, it can be done in matters of minutes with the help of ProgSynth which has helper functions to help you focus on what really matters here: the synthesis.
The check function is a python function, it can contain whatever code you might need to check that a given program satisfy your constraints. An example of such a function is to check whether your program matches the given examples of input-output pairs.
What do you get out?
At the end you get a program tthat satisfies your condition, or if all programs have been enumerated, you get that there is no program in the given grammar that matches your specification. In practice the negative answer is never given since the number of programs grow exponentially, it would be infeasible to enumerate them all, so we recommend to use a timeout after which the search is stopped.
How does that work?
This section attemps to give you a high-level overview of how it works.
Here is a figure that gives you a rough overview of how it works:
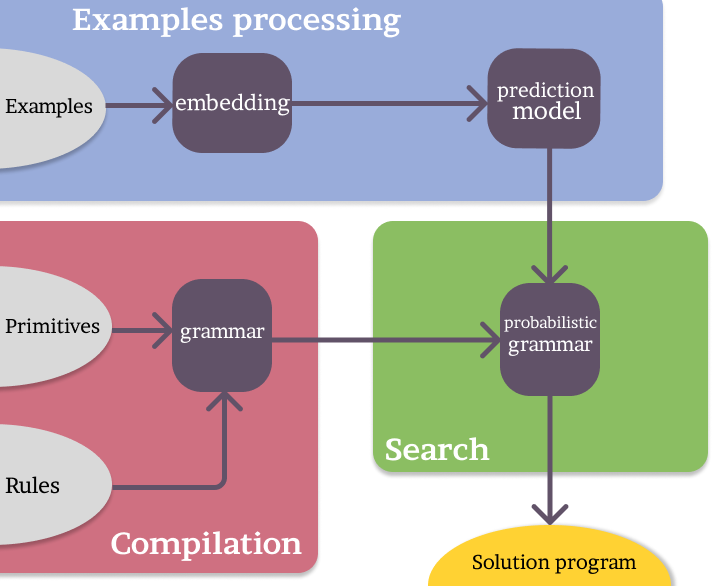
Compilation
The language that you give is typed and you also give at least a depth constraint, to guarantee that programs have a maximum depth. Of course, you also specify the type of the program that you want to generate. This language is built into a context-free grammar (CFG).
If you have specified constraints through sharpening, then the constraints and the grammar are compiled into deterministic bottom-up tree automata. The intersection is then computed and transformed back into a CFG.
Prediction (Optional in the future)
If you have trained a model to produce program distributions over grammars, then you can use this step otherwise fear not because this will not be mandatory in the future.
A model (often a neural network) takes as an input your specification and other information that you trained it on and then produce a vector which we translate into probabilities for our CFG. That means that we have a probabilistic CFG (PCFG).
Splitting (Optional)
You have multiple CPUs and you want to parallelize the search?
Well, we have a split function that takes a PCFG and split it into as many fragments as you want.
This means that each fragment of the original PCFG is independent that is no other fragment contains its programs.
In other words, with splitting you can have linear speed-up in your enumeration with the number of CPUs.
Do note that while splitting is provided in ProgSynth we do not provide the parallelization framework, you will have to do it yourself.
Enumeration
This PCFG actually gives us an order over programs. Programs can be ordered by their probability. Therefore ProgSynth will enumerate programs in order of decreasing probability. That means that the most likely program will be enumerated first. All of the time for synthesis is spent here and in most cases the cost to call your check function is what bounds the runtime.
When a program is enumerated, we call your check function with the program as argument.
If your function returns True then we just stop here and returns the program, otherwise we continue.